Results
Single image decomposition

Multi-view images under varying illumination
Overview
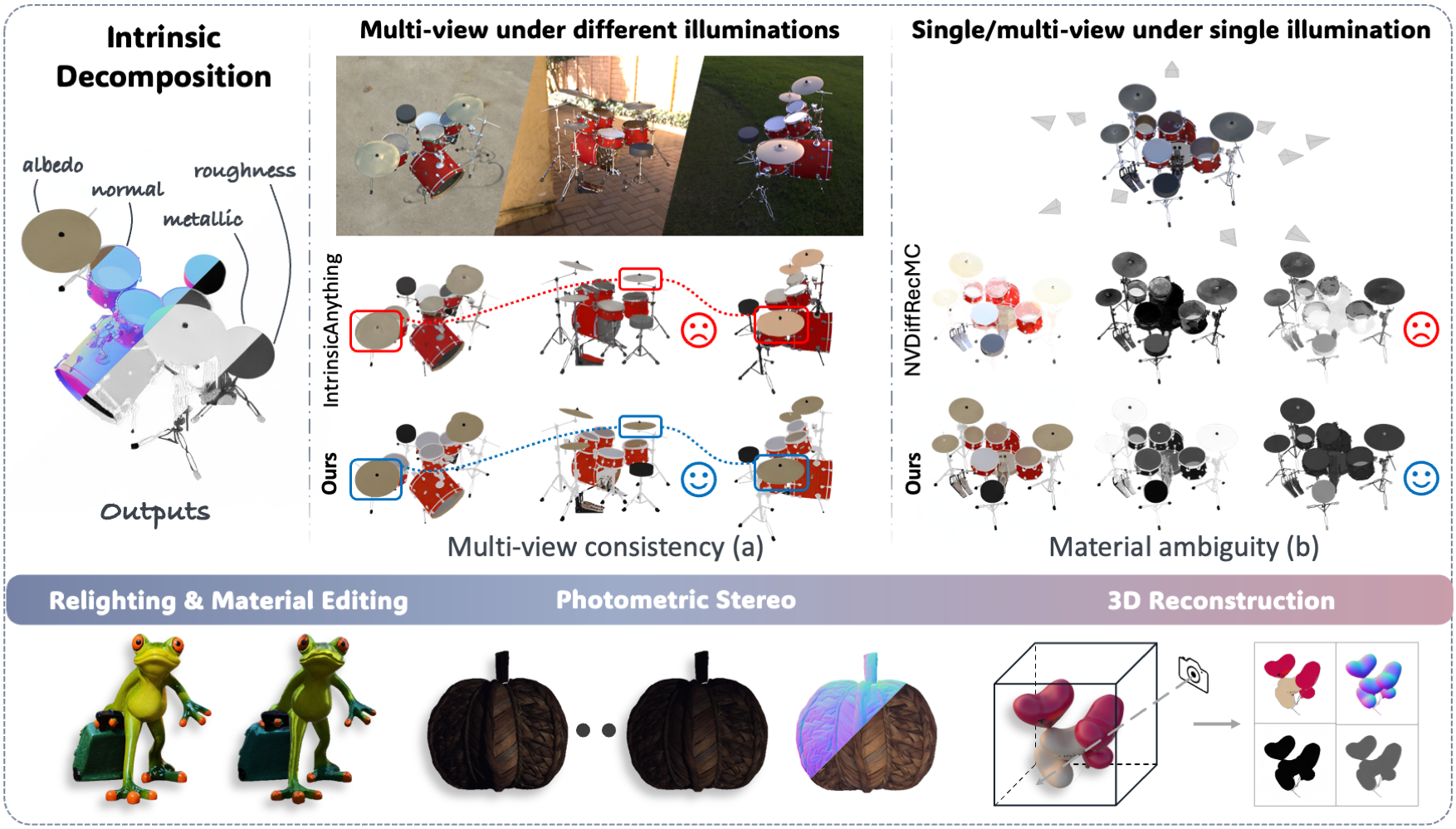
IDArb tackles intrinsic decomposition for an arbitrary number of views under unconstrained illumination. Our approach (a) achieves multi-view consistency compared to learning-based methods and (b) better disentangles intrinsic components from lighting effects via learnt priors compared to optimization-based methods. Our method could enhance a wide range of applications such as image relighting and material editing, photometric stereo, and 3D reconstruction.
Architecture

Our training batch consists of \( N\) input images, sampled from \( N_v\) viewpoints and \( N_i\) illuminations. The latent vector for each image is concatenated with Gaussian noise for denoising. Intrinsic components are divided into three triplets (\( D=3\)): Albedo, Normal and Metallic&Roughness. Specific text prompts are used to guide the model toward different intrinsic components. For attention block inside UNet, we introduce cross-component and cross-view attention module into it, where attention is applied across components and views, facilitating global information exchange.
Arb-Objaverse Dataset
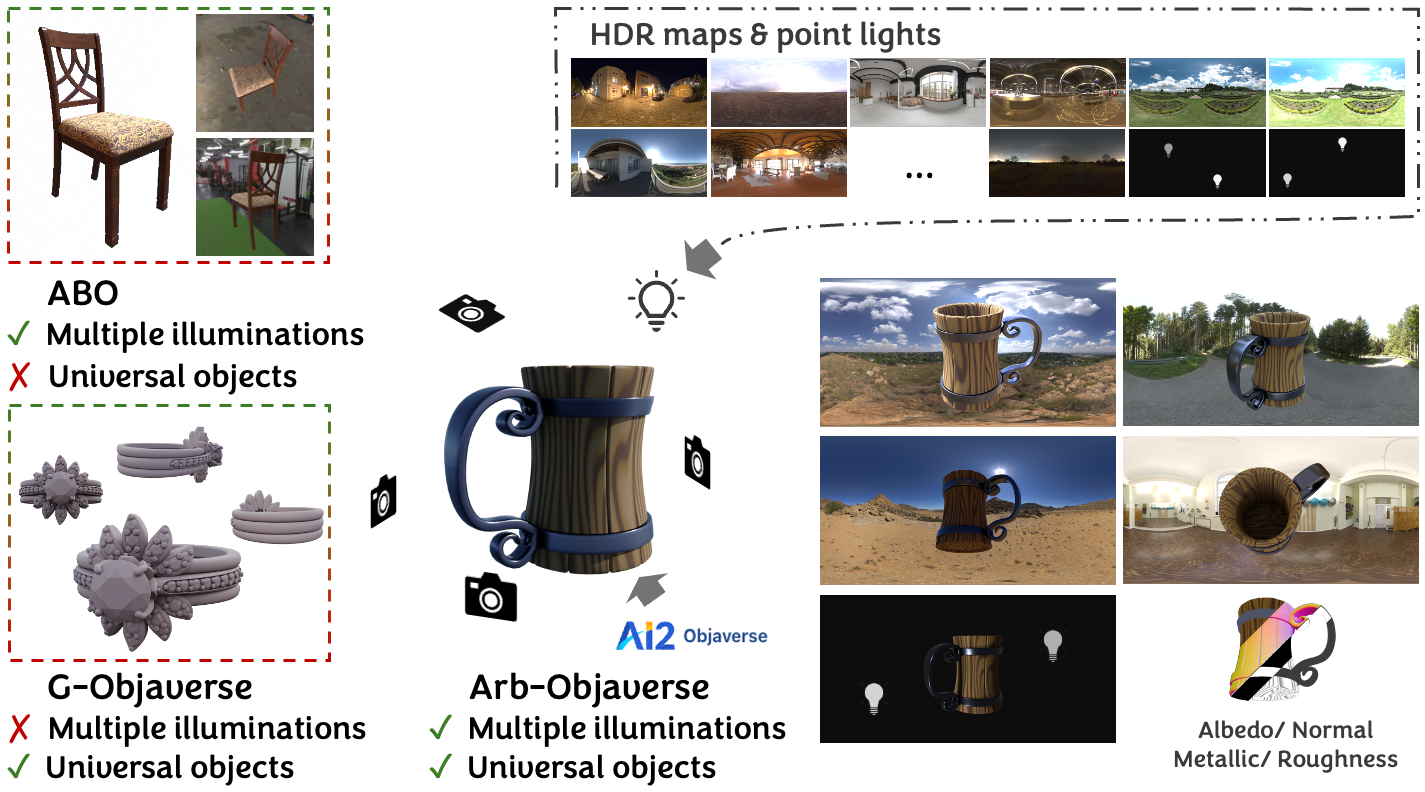
Our custom dataset contains 5.7M multi-view RGB images and intrinsic components with varying illumination scenarios. For each object, we render 12 views. For each viewpoint, we render 7 images under different lighting conditions. Six images are illuminated by randomly sampled high-dynamic range (HDR) environment maps. The last image is illuminated by two point light sources randomly positioned on a surrounding shell.